Documentation Index
Fetch the complete documentation index at: https://pycrm.xyz/llms.txt
Use this file to discover all available pages before exploring further.
Counterfactual Q-Learning in Letter World
The Concept
Counterfactual Q-Learning leverages the structured nature of RM/CRMs to generate additional “what-if” experiences that the agent can learn from, without actually having to explore those states.
By utilizing the symbolic representation in the CRM, we can:
- Infer consequences of different actions
- Update multiple state-action values at once
- Accelerate learning significantly
Implementation Comparison
Let’s compare standard Q-Learning with Counterfactual Q-Learning in the Letter World environment.
Standard Q-Learning
from examples.introduction.core.ground import LetterWorld
from examples.introduction.core.label import LetterWorldLabellingFunction
from examples.introduction.core.machine import LetterWorldCountingRewardMachine
from examples.introduction.core.crossproduct import LetterWorldCrossProduct
# 1. Create the ground environment
ground_env = LetterWorld()
# 2. Create the labelling function
lf = LetterWorldLabellingFunction()
# 3. Create the CRM
crm = LetterWorldCountingRewardMachine()
# 4. Create the cross-product MDP
env = LetterWorldCrossProduct(
ground_env=ground_env,
crm=crm,
lf=lf,
max_steps=500,
)
# Hyperparameters
EPISODES = 5000
LEARNING_RATE = 0.01
DISCOUNT_FACTOR = 0.99
EPSILON = 0.1
# Initialize Q-table
q_table = defaultdict(lambda: np.zeros(env.action_space.n))
# Train standard Q-learning agent
for episode in range(EPISODES):
obs, _ = env.reset()
done = False
while not done:
# Epsilon-greedy policy
if np.random.random() < EPSILON:
action = np.random.randint(env.action_space.n)
else:
action = int(np.argmax(q_table[tuple(obs)]))
# Execute action
next_obs, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Q-learning update
if done:
td_target = reward
else:
td_target = reward + DISCOUNT_FACTOR * np.max(q_table[tuple(next_obs)])
td_error = td_target - q_table[tuple(obs)][action]
q_table[tuple(obs)][action] += LEARNING_RATE * td_error
obs = next_obs
Counterfactual Q-Learning
# Initialize Q-table for counterfactual agent
q_table = defaultdict(lambda: np.zeros(env.action_space.n))
# Train counterfactual Q-learning agent
for episode in range(EPISODES):
obs, _ = env.reset()
done = False
while not done:
# Epsilon-greedy policy
if np.random.random() < EPSILON:
action = np.random.randint(env.action_space.n)
else:
action = int(np.argmax(q_table[tuple(obs)]))
# Execute action
next_obs, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
# Generate and learn from counterfactual experiences
for o, a, o_, r, d, _ in zip(
*env.generate_counterfactual_experience(
env.to_ground_obs(obs),
action,
env.to_ground_obs(next_obs),
),
strict=True,
):
if not d:
q_table[tuple(o)][a] += LEARNING_RATE * (
r
+ DISCOUNT_FACTOR * np.max(q_table[tuple(o_)])
- q_table[tuple(o)][a]
)
else:
q_table[tuple(o)][a] += LEARNING_RATE * (r - q_table[tuple(o)][a])
# Standard Q-learning update for actual experience
if done:
td_target = reward
else:
td_target = reward + DISCOUNT_FACTOR * np.max(q_table[tuple(next_obs)])
td_error = td_target - q_table[tuple(obs)][action]
q_table[tuple(obs)][action] += LEARNING_RATE * td_error
obs = next_obs
The key difference is the addition of generate_counterfactual_experience(), which provides additional learning signals without requiring actual exploration.
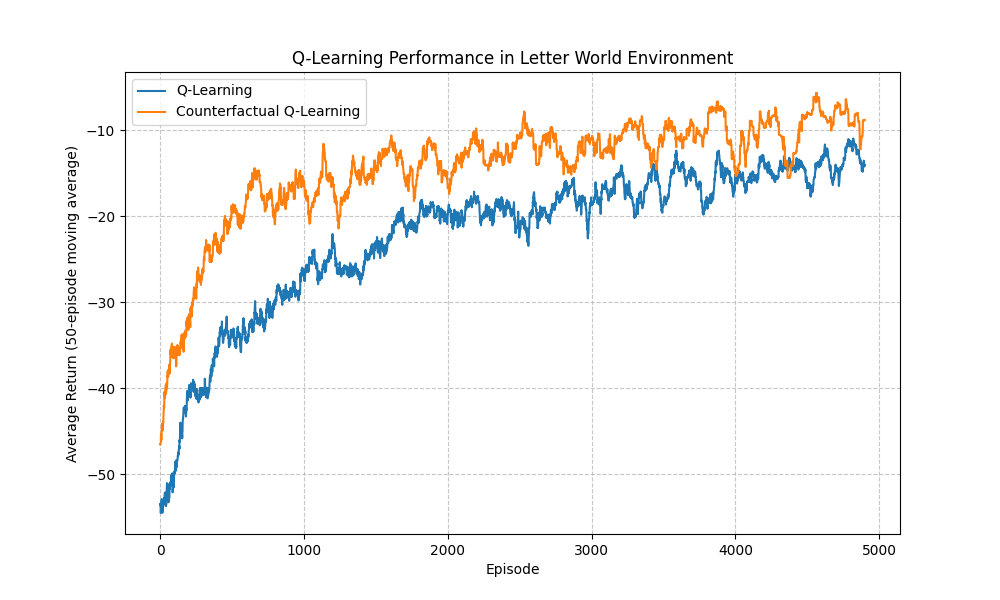
- Counterfactual Q-Learning (orange) learns much faster and achieves higher returns
- Standard Q-Learning (blue) requires many more episodes to approach similar performance
- Both eventually converge, but counterfactual learning requires significantly fewer samples
How It Works
The counterfactual learning process works through these steps:
- The agent takes an action in the environment
- The CRM uses its symbolic structure to infer what would have happened for other state-action pairs
- These counterfactual experiences are used to update multiple Q-values simultaneously
- This process effectively multiplies the learning signal from each real experience
Code Breakdown: Generating Counterfactual Experiences
The magic happens in the generate_counterfactual_experience method:
def generate_counterfactual_experience(self, ground_obs, action, next_ground_obs):
# Current position and CRM state
current_pos = self.ground_env.decode_obs(ground_obs)
next_pos = self.ground_env.decode_obs(next_ground_obs)
# Generate all possible experiences based on CRM structure
obs_list = []
action_list = []
next_obs_list = []
reward_list = []
done_list = []
info_list = []
# For each possible CRM state...
for crm_state in self.crm.states:
# Create counterfactual experience
# [implementation details]
return obs_list, action_list, next_obs_list, reward_list, done_list, info_list
Benefits and Applications
Counterfactual Q-Learning offers several advantages:
- Sample Efficiency: Learns from fewer real-world interactions
- Faster Convergence: Reaches optimal policy more quickly
- Better Exploration: Effectively explores the state space
- Interpretability: Leverages symbolic structure of CRMs
This approach is particularly useful in environments where:
- Exploration is expensive or risky
- Task structures have clear symbolic representations
- Sample efficiency is critical
Conclusion
Counterfactual Q-Learning demonstrates a powerful approach to accelerating learning in environments with structured symbolic representations. By leveraging the CRM’s symbolic structure, we can generate additional learning experiences that significantly improve sample efficiency and convergence speed.